業務背景
在現代化企業管理中,利用數據分析進行決策支持已成為重要手段,其中包括:過程控制、產能預測、市場決策等等。
在各類業務場景中如何用數字直觀地描述指標與指標之間的相關性是一個重要命題,該類業務大多基于回歸分析法,回歸分析法通過對過去的數據進行采樣來構建回歸模型,從而為決策和行動提供依據和建議。當回歸模型擬合不正確,會誤導企業決策的方向,浪費大量人力、物力、財力,給企業造成巨大的損失。因此,對回歸模型進行診斷是不可或缺的步驟。即判斷回歸模型是否正確、理想?換句話說,模型是否很好的提取了樣本的規律信息。國工智能MAI平臺提供了基于殘差檢驗進行回歸模型評估的科學算法。
殘差檢驗的內容
經典且理想的回歸模型的前提條件是:1.隨機誤差項各項之間無序列相關;2.隨機誤差項服從正態分布;3.隨機誤差項方差都相同或是固定的常數。(在實際應用中,隨機誤差項用殘差來代替)
滿足上述三個假設條件說明回歸模型是理想的。殘差是樣本值(藍點)與回歸直線(紅線)上的值(又稱回歸擬合值)之間的差,紅線可由數據大腦擬合回歸算法得出,具體見下圖。殘差檢驗即檢查經過回歸擬合后得到的殘差是否滿足上述三個條件。如果違背了上述其中之一的假設條件,就不是經典的線性回歸模型,這樣的模型用普通最小二乘法來估計往往失效,最后擬合出來的模型往往是有誤的,預測的效果也大打折扣。
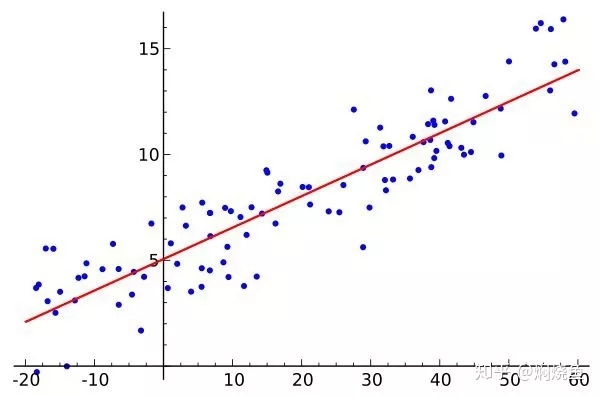
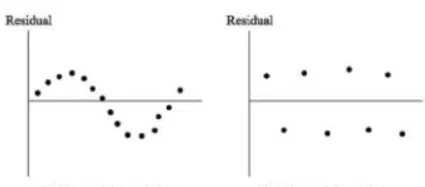
圖2 序列正相關
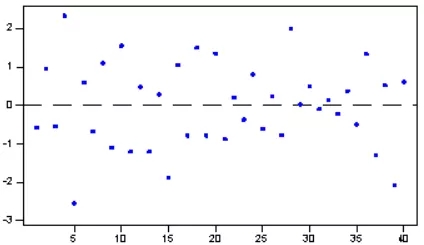
所有線性回歸模型。
應用場景
化工、釀造等裝置性行業的過程控制,往往是多變量共同作用。為了做好過程控制,實現“以因素管理結果",我們運用回歸分析的統計技術尋找規律,并用于生產過程控制。例如,啤酒釀造過程中成品啤酒的泡特性(秒),是直接關系到啤酒口感的技術要求。技術和經驗表明中間產物的總氮含量X對于需要滿足的泡沫時間Y (秒)有影響。數據如下:
表1
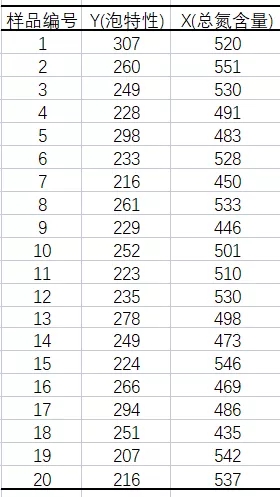
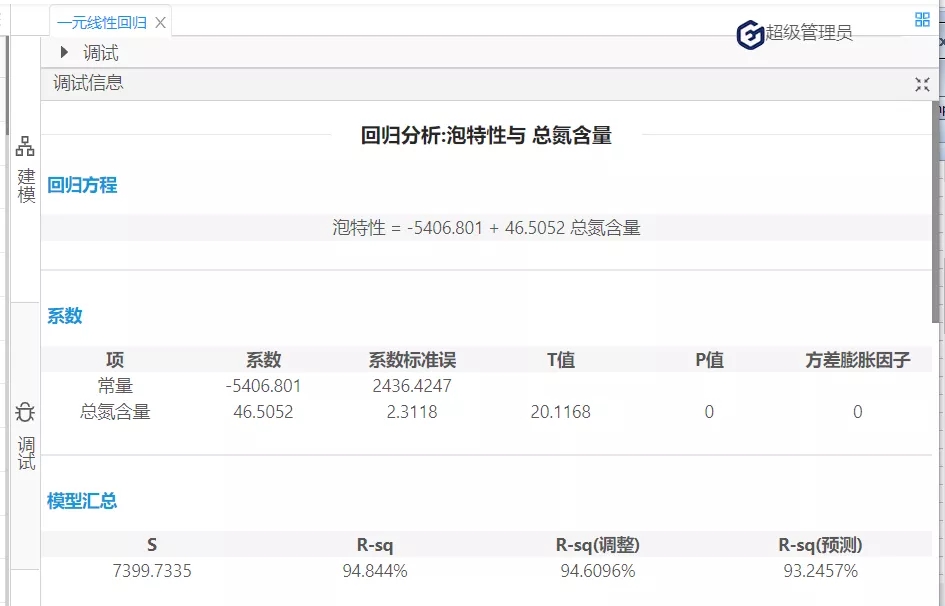
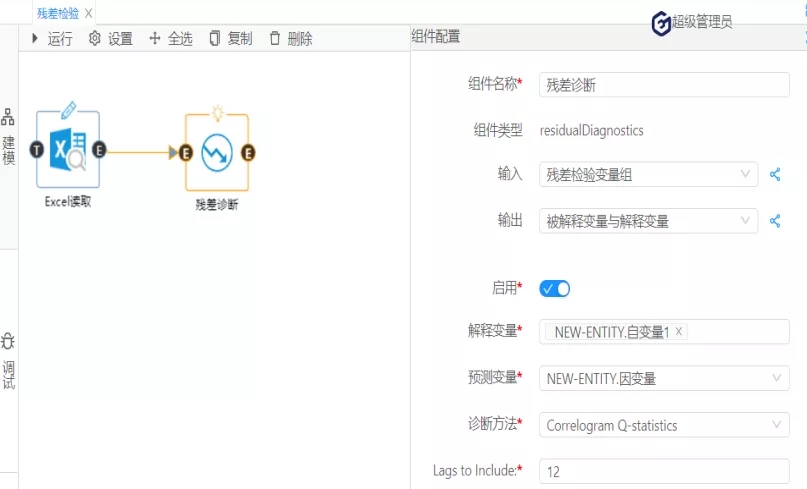
圖6
運行結果:
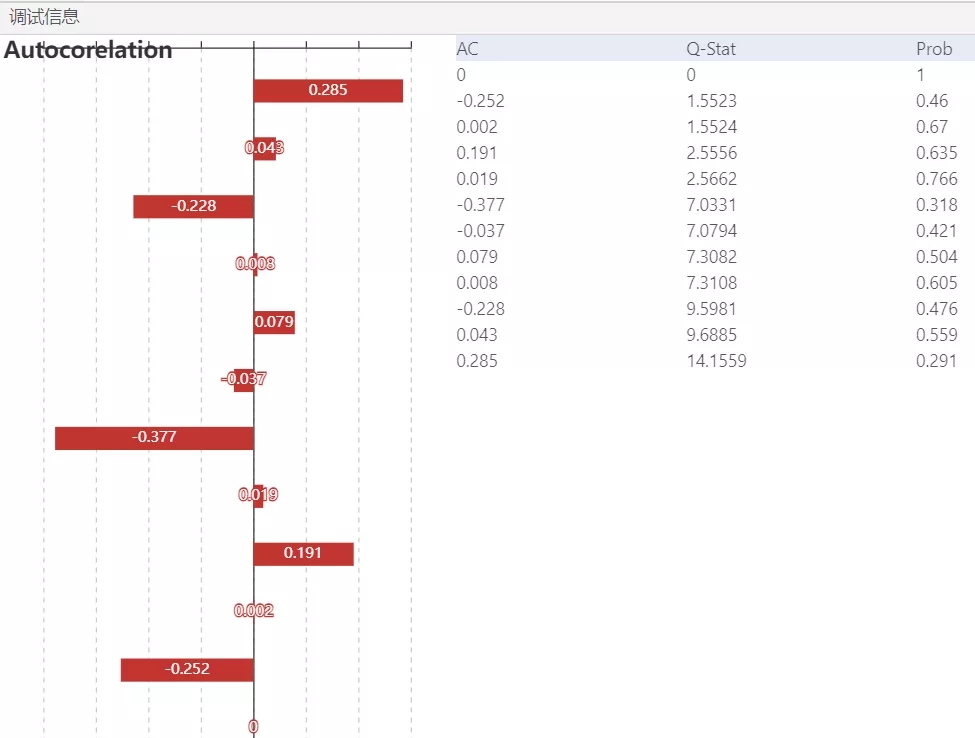
圖 7
根據圖7可知,無論滯后階數為幾,其p值都大于0.1的顯著性水平,接受原假設,殘差序列不存在序列相關。
接下來,進行殘差檢驗的第二個方面:殘差序列正態性檢驗。(原假設:序列服從正態分布)在診斷方法下拉列表選擇:Histigram-Normality-Test;如圖3:
圖 8
運行結果:
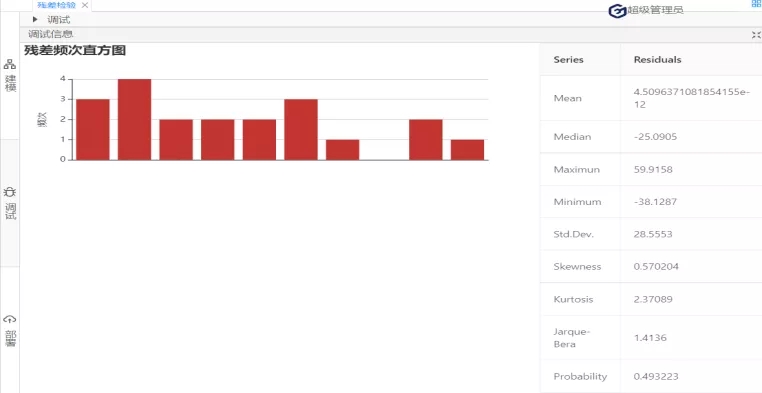
圖 9
根據圖9可知,Jarque-Bera(JB)統計量的值為1.4136,它服從自由度為2的卡方分布,在0.1的顯著性水平下,其臨界值=4.605,故JB統計量<臨界值,接受原假設,該殘差序列服從正態分布。最后,進行殘差檢驗的第三個方面:檢驗方差是否相同。(原假設:序列方差相等)在診斷方法下拉列表選擇:Heteroskedasticity-Tests(懷特檢驗);如圖10:
圖10
運行結果:
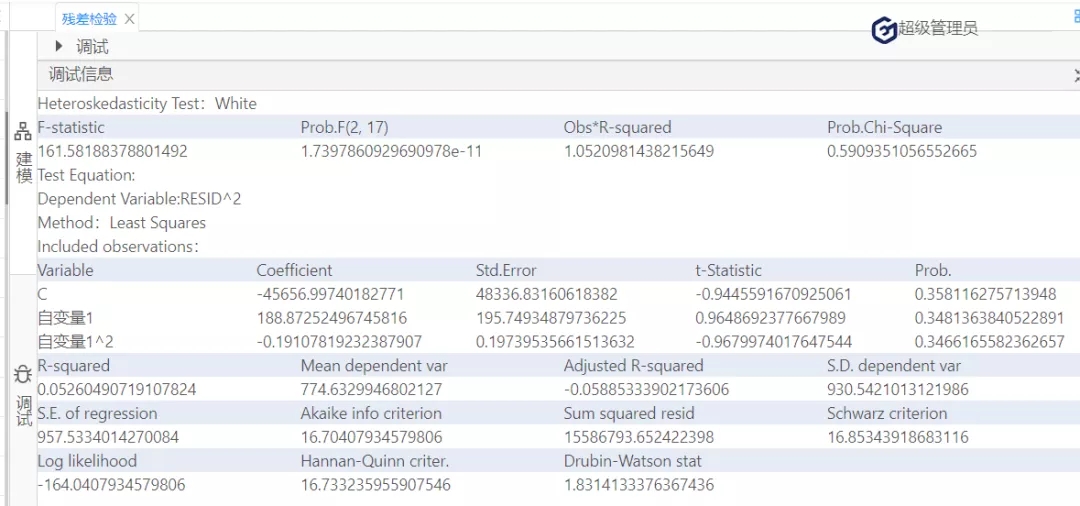
圖11
根據圖11可知,懷特檢驗統計量的值為1.052,它也服從自由度為2的卡方分布,在0.1的顯著性水平下,其臨界值=4.605,懷特檢驗統計量值<臨界值,接受原假設,該殘差序列存在方差相等的情況。
綜上,在啤酒的泡特性與總氮含量的一元線性回歸模型中,該殘差序列不存在序列相關,服從正態分布,且方差相同,上述的三個條件都滿足,說明回歸模型擬合不錯且準確,可使用該模型進行預測。
在下一批生產中,若X(總氮含量)=130,則Y(泡特性)的預測值=-5406.801+46.51*130=639.3(秒),以此類推,能夠預測到未來若干次生產中的成品啤酒的泡特性,可通過降低總氮含量等措施控制啤酒的泡特性,從而實現生產控制,實現效益最大化的目標。(具體預測及回歸模型含義國工數據大腦多元線性回歸在化學研發成本的預測一文)
 2023-09-28
月圓人圓,國工與您賀中秋迎國慶!
2023-09-28
月圓人圓,國工與您賀中秋迎國慶!
中秋節是中國傳統節日之一,也是一年中最重要、最盛大的節日之一。在這一天,以明亮的月亮和家人團聚為特點,承載著人們無盡的思念和美好的祝福。 國慶、中秋兩節遇, 合家團圓精神俱。 團團圓圓過中秋, 歡歡喜喜
 2023-09-01
國工智能與鎂伽科技啟動戰略合作
2023-09-01
國工智能與鎂伽科技啟動戰略合作
2023年8月28日,國工智能與鎂伽科技舉行戰略合作簽約儀式,國工智能董事長柳彥宏與鎂伽科技創始人兼首席執行官黃瑜清先生代表雙方簽訂正式戰略合作協議,標志著AI輔助化工研發領先者、智能自動化實驗室引領者開啟強強聯合發展之路。&n
 2023-05-30
點亮創新發展精神火炬,勇攀人工智能科技高峰
2023-05-30
點亮創新發展精神火炬,勇攀人工智能科技高峰
創新是一個民族進步的靈魂,是一個國家興旺發達的不竭動力,也是中華民族最深沉的民族稟賦。在激烈的國際競爭中,惟創新者進,惟創新者強,惟創新者勝。 5月27日
4月6日,陜西2023年一季度重點項目觀摩活動走進渭南。當日,觀摩組深入蒲城海泰高端液晶顯示材料生產項目等重點項目建設現場進行觀摩。 作為國工智能的重要合作伙伴,近年來,

